
An alternative to business-facing TDD
The value of programmer TDD is well established. It’s natural to extrapolate that practice to business-facing tests, hoping to obtain similar value. We’ve been banging away at that for years, and the results disappoint me. Perhaps it would be better to invest heavily in unprecedented amounts of built-in support for manual exploratory testing.
In 1998, I wrote a paper, “When should a test be automated?“, that sketched some economics behind automation. Crucially, I took the value of a test to be the bugs it found, rather than (as was common at the time) how many times it could be run in the time needed to step through it manually.
My conclusions looked roughly like the following:
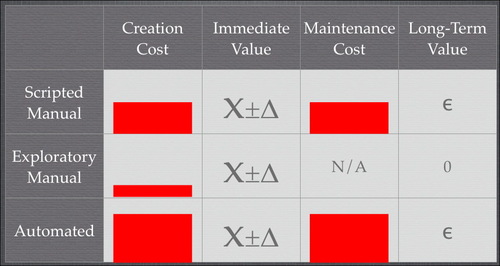
Scripted tests, be they automated or manual, are expensive to create (first column). Manual scripts are cheaper, but they still require someone to write steps down carefully, and they likely require polishing before they can truly be followed by someone else. (Note: height of bars not based on actual data.)
In the second column, I assume that a particular set of steps has roughly the same chance of finding a bug whether executed manually or by a computer, and whether the steps were planned or chosen on the fly. (I say “roughly” because computers don’t get bored and miss bugs, but they also don’t notice bugs they weren’t instructed to find.)
Therefore, if the immediate value of a test is all that matters, exploratory manual testing is the right choice. What about long-term value?
Assume that exploratory tests are never intentionally repeated. Both their long-term cost and value are zero. Both kinds of scripted tests have quite substantial maintenance costs (especially in that era, when testing was typically done through an unmodified GUI). So, to pull ahead of exploratory tests in the long term, scripted tests must have substantial bug-finding power. Many people at that time observed that, in fact, most tests either found a bug the first time they were run or never found a bug at all. You were more likely to fix a test because of an intentional GUI change than to fix the code because the test found a bug.
So the answer to “when should a test be automated?” was “not very often”.
Programmer TDD changes the balance in two ways:

-
New sources of value are added. Extremely rapid feedback reduces the cost of debugging. (Most bugs strike while what you did to create them is fresh in your mind.) Many people find the steady pace of TDD allows them to go faster, and that the incremental growth of the code-under-test makes for easier design. And, most importantly as it turns out, the need to make tests run fast and reduce maintenance cost leads to designs with good properties like low coupling and high cohesion. (That is, properties that previously were considered good in the long term—but were routinely violated for short-term gain—now had powerful short-term benefits.)
-
Good design and better programmer tools dramatically lowered the long-term cost of tests.
So, much to my surprise, the balance tipped in favor of automation—for programmer tests. It’s not surprising that many people, including me, hoped the balance could also tip for business-facing tests. Here are some of the hoped-for benefits:
-
Tests might clarify communication and avoid some cases where the business asks for something, the team thinks they’ve delivered it, and the business says “that’s not what I wanted.”
-
They might sharpen design thinking. The discipline of putting generalizations into concrete examples often does.
-
Programmers have learned that TDD supports iterative design of interfaces and behavior. Since whole products are also made of interfaces and behavior, they might also benefit from designers who react to partially-finished products rather than having to get it right up front.
-
Because businesses have learned to mistrust teams who show no visible progress for eight months (at which point, they ask for a slip), they might like to see evidence of continuous progress in the form of passing tests.
-
People often need documentation. Documentation is often improved by examples. Executable tests are examples. Tests as executable documentation might get two benefits for less than their separate costs.
-
And, oh yeah, tests could find regression bugs.
So a number of people launched off to explore this approach, most notably with Fit. But Fit hasn’t lived up to our hopes, I think. The things that particularly bother me about it are:
-
It works well for business logic that’s naturally tabular. But tables have proven awkward for other kinds of tests.
-
In part, the awkwardness is because there are no decent HTML table editors. That inhibits experimentation: if you don’t get a table format right the first time, you’re tempted to just leave it.
Note: I haven’t tried ZiBreve. By now, I should have. I do include Word, Excel, and their OpenOffice equivalents among the ranks of the not-decent, at least if you want executable documentation. (I’ve never tried treating .doc files as the real tests that are “compiled” into HTML before they’re executed.)
-
Fit is not integrated into programmer editors the way xUnit is. For example, you can’t jump from a column name to the Java method that defines it. Partly for this reason, programmers tend to get impatient with people who invent new table formats—can’t they just get along with the old one?
With my graphical tests, I took aim at those sources of friction. If I have a workflow test, I can express it as boxes and arrows:
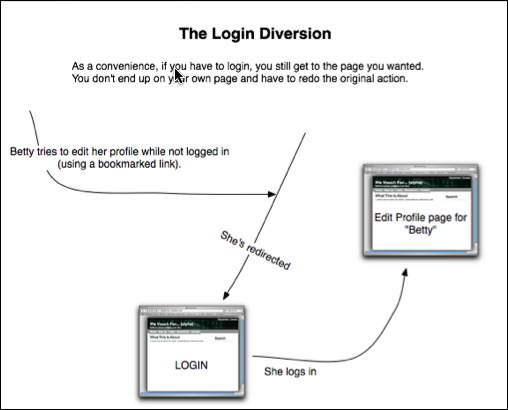
I translate the graphical documents into ordinary xUnit tests so that I can use my familiar tools while coding. The graphical editor is pretty decent, so I can readily change tests when I get better ideas. (There are occasional quirks where test content has changed more than it looks like it has. That aspect of using Fit hasn’t gone away entirely.)
I’ve been using these tests, most recently on wevouchfor.org—and they don’t wow me.  While I almost always use programmer TDD when coding (and often regret skipping it when I don’t), TDD with these kinds of tests is a chore. It doesn’t feel like enough of the potential value gets realized for the tests to be worth the cost.
While I almost always use programmer TDD when coding (and often regret skipping it when I don’t), TDD with these kinds of tests is a chore. It doesn’t feel like enough of the potential value gets realized for the tests to be worth the cost.
-
↓ Writing the executable test doesn’t help clarify or communicate design. Let me be careful here. I’m a big fan of sketching things out on whiteboards or paper:

That does clarify thinking and improve communication. But the subsequent typing of the examples into the computer is work that rarely leads to any more design benefits.
-
↔ Passing tests do continuously show progress to the business, but… Suppose you demonstrate each completed story anyway, at an end-of-iteration demo or (my preference) as soon as it’s finished. Given that, does seeing more tests pass every day really help?
-
↑ Tests do serve as documentation (at least when someone takes the time to surround them with explanatory text, and if the form and content of the test aren’t distorted to cram a new idea into existing test formats).
-
↑ The word I’m hearing is that these tests are finding bugs more often than I expected. I want to dig into that more: if they’re the sort of “I changed this thing over here and broke that supposedly unrelated thing over there” bugs that whole-product regression tests are traditionally supposed to find, that alone may justify the expense of test automation—unless I can find a way to blame it on inadequate unit tests or a need to rejigger the app.
-
↓ (This is the one that made me say “Eureka!”) Tests alone fail at iterative product design in an interesting way. Whenever I’ve made significant progress implementing the next chunk of workflow or other GUI-visible change, I just naturally check what I’ve done through the GUI. Why? This checking makes new bugs (ones the automated tests don’t check for) leap out at me. They also sometimes make me slap my forehead and say, “What I intended here was stupid!”
But if I’m going to be looking at the page for both bugs and to change my intentions, I’m really edging into exploratory testing. Hmm… What if an app did whatever it could to aid exploratory testing? I don’t mean traditional testability features like, say, a scripting interface; I mean a concerted effort to let exploratory testers peek and poke at anything they want within the app. (That may not be different than my old motto “No bug should be hard to find the second time,” but it feels different.)
So, although features of Rails like not having to restart the server after most code changes are nice, I want more. Here’s an example.
The following page contains a bug:
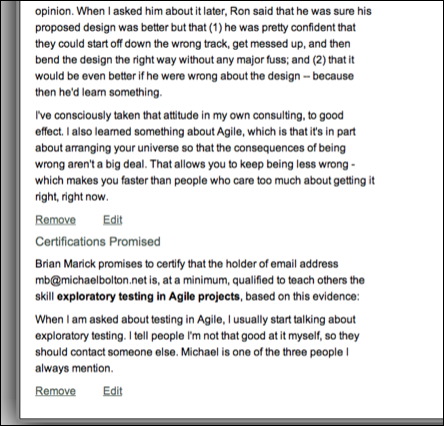
Although you can’t see it, the bottom two links are wrong. They are links to /certifications/4 instead of /promised_certifications/4.
-
Unit tests couldn’t catch that bug. (The two methods that create those types of links are tested and correct; I just used the wrong one.)
-
One test of the action that created the page could have caught the bug, but did not. (To avoid maintenance problems, that test checked the minimum needed to convince me that the correct “certifications” had been displayed. I assumed that if they were displayed at all, the unit tests meant they were displayed correctly. That was actually almost right—every character outside the link’s
hrefvalue was correct.) -
I missed the bug when I checked the page. (I suspect that I did click one of the links, but didn’t notice it went to the wrong place. If so, I bet I missed the wrongness because I didn’t have enough variety in the test data I set up—ironic, because I’ve been harping on the importance of “irrelevant” variety since 1994.)
-
A user had no trouble finding the bug when he tried to edit one of his promised certifications and found himself with a form for someone else’s already-accepted certification. (Had he submitted the form, it would have been rejected, but still.)
That’s my bug: a small error in a big pile of HTML the app fired and forgot.
Suppose, though, that the app created and retained an object representing the page. Suppose further that an exploration support app let you switch to another view of that object/page, one that highlights link structure and downplays text:
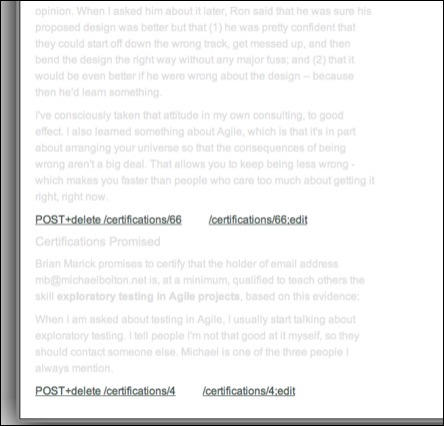
To the eyes of someone who just added promised certifications to that page, the wrong link targets ought to jump out.
There’s more that I’d like, though. The program knows more about those links than it included in the HTTP Response body. Specifically, it knows they link to a certain kind of object: a PromisedCertification. I should be able to get a view of that object (without committing to following the link). I should be able to get it in both HTML form and in some raw format. (And if the link-to-be-displayed were an object in its own right, I would have had a place to put my method, and I wouldn’t have used the wrong one. Testability changes often feed into error prevention.)
And so on… It’s easy enough for me to come up with a list of ways I’d like the app to speak of its internal workings. So what I’m thinking of doing is grabbing some web framework, doing what’s required to make it explorable, using it to build an app, and also building an exploration assistant in RubyCocoa (allowing me to kill another bird with this stone).
To be explicit, here’s my hypothesis:
An application built with programmer TDD, whiteboard-style and example-heavy business-facing design, exploratory testing of its visible workings, and some small set of automated whole-system sanity tests will be cheaper to develop and no worse in quality than one that differs in having minimal exploratory testing, done through the GUI, plus a full set of business-facing TDD tests derived from the example-heavy design.
We shall see, I hope.






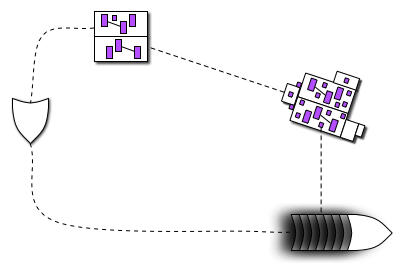
 of what she wants. The programmers produce code
of what she wants. The programmers produce code  from it. As a user runs
from it. As a user runs  that code, she can at any moment get a bundle of pictures
that code, she can at any moment get a bundle of pictures  that she can point at during a conversation with the producer and other users. That might lead to some new driving examples
that she can point at during a conversation with the producer and other users. That might lead to some new driving examples