
Four implementation styles for workflow tests
Many of the tests that currently use browser-driving tools like Selenium, Watir, or Silk could use different implementation technologies. In the rest of this note, I describe the pros and cons of browser driving, HTTP driving, the Rails variant of HTTP driving, and app-layer driving.
Context
There are certain kinds of automated business-facing tests whose job is to show how a user can accomplish some task. I’m going to call them “workflow tests.” They usually involve (1) navigation through the application and (2) judicious checking that the application is where it should be with at least some of the right data visible. (I mention “judicious” because I believe demonstrations that a page contains every bit of what it should contain ought to be done by other tests and not repeated in these. Stripping the checking down will increase maintainability at a most-likely-negligible risk.)
The purposes of these tests are:
-
to help the programmer understand what the business wants.
-
to help everyone agree what it means to say the current story is done.
-
to help the product director (or perhaps a user experience designer) to think through what it is that she wants—to be a concrete way of exploring ideas.
-
to find bugs introduced by programmers making changes. However: if these tests catch many “regression” bugs, I think you’re doing something wrong. Most should be caught earlier, by other tests. Fix those tests, or fix the infrastructure for your app to make more kinds of bugs impossible or unlikely.
Here’s an example of such a test:

Except for usual spacing and indentation, it looks pretty much like English. (One thing that may not be clear is that the parenthetical comments are what the test checks.) A natural language is appropriate, given a workflow test’s audience. But, because computers are so blasted picky, you have to clutter the test up a bit. The following is a Ruby version of that test:

It doesn’t take much practice for a product director to ignore the clutter.
In each case below, the test continues to look the same. That means someone has to write a translation layer that converts the language of the test to some pickier, more detailed, more techie language. The pros and cons of each approach are the pros and cons of its characteristic translation layer.
(Note: With tools like Watir and Selenium, you could write the tests in the language of browser actions—click and the like—but that hampers all but the least important goal of workflow tests. Since it’s also a maintainability nightmare, I’m going to ignore that approach. Even with button-pressing tools, you hide the button pressing behind the translation layer.)
Driving the browser 
In the first approach, the translation layer need know nothing about the app other than that it’s driven through a browser. There’s a server out there somewhere, but no one cares.
This style makes it easiest to learn how to write the translation layer. Both what you’re translating from (English) and to (buttons, text fields) are familiar to most anyone involved in computers. As a result, you can start testing quickly. The tests are satisfying because they test what the user sees. The app is used exactly as a real user would use it.
There are difficulties, though. Because the user interface can change a lot, the translation layer tends to be a maintainability problem. You can also run into technical roadblocks. One week, I was at a site that was blocked trying to figure out how to make Watir deal with certificate popups in Internet explorer. (I posted my solution.) Two weeks later, the problem was making Selenium deal with IE’s file-upload popups. (That time, we moved to a different technology.)
Finally, this style doesn’t mesh smoothly with test-driven design. At least it doesn’t feel that way to me—I could be wrong&mdash. The problem is you have to decide fiddly little details of the interface (”what’s the name of the submit button?”) before you can even see the test fail.
Driving HTTP
Tools like HTTPUnit and Canoo WebTest take a different approach. They know that the browser has to speak to the application server via the HTTP protocol. Instead of driving the browser, they produce and consume HTTP, driving the app directly. In effect, they pretend to be the browser.
Their translation layer is likely more maintainable. It doesn’t have to fiddle with a bunch of typing and button presses—it merely packages up the data into a relatively simple structure and sends it off. Because these tests work below the browser, they can avoid the technical complications browsers bring (like the popup problems I mentioned above).
On the other hand, because tests don’t involve the browser, they can’t check everything that the browser does. Even if the tool you’re scripting handles Javascript (as HTTPUnit says it does), you don’t know if its Javascript has the same idiosyncrasies as Internet Explorer’s does. If poking at Javascript is part of what your judicious set of workflow checks, you might have to fall back on manual work for some tests or trust that earlier tests suffice. (For example, you might have tested your Javascript in isolation with JSUnit, or you may rely on well-tested javascript-generating components like Rails or the Google Web Toolkit.)
I’ve found that people—technical and nontechnical alike—have an almost instinctive aversion to not “testing what the user sees.” I think that reaction is overblown, but it’s nevertheless a real thing you need to cope with if you go this route.
Finally, this approach is harder to learn than the previous one, and I think the scripting skills need to be stronger.
The Rails variant on driving HTTP 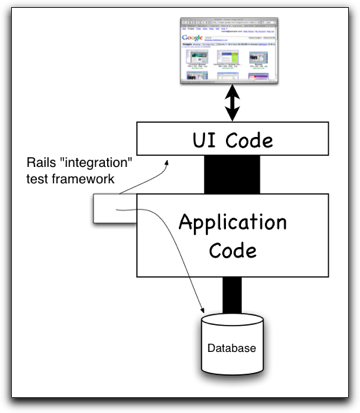
Rails extends the previous idea by linking the test code into the main body of the application. That is, rather than construct an HTTP Request that flies across some network, is received by the app, funneled through some application-wide Request-handling code, and then delivered to the code that handles that particular request, a Rails integration test skips the network. From inside the app, it calls the application-wide Request-handling code directly.
The main additional advantage to this approach is that tests can make use of application support code. For example, a test that wants to check whether an order has really been saved to the database doesn’t have to open a database connection and SQL around through it; it can use the Rails object-relational-database mapping code (which is so nice and easy that it will make you cry).
Easier observation means fewer distorted tests. Sometimes a step in a workflow causes something to happen in the application, but that something isn’t immediately visible. Without direct access to support code, these tests often have to go through some convoluted sequence of steps to let the test either see or infer that the right thing happened.
I also expect—although I do not know from personal experience—that this integration will, in the end, considerably reduce the total effort of making the translation layer.
The first difficulty of this approach is that someone must have built the internal test-support framework already. Often, there isn’t one. It may not even be possible for a test to use the application-wide Request-handling code without jumping through a ridiculous number of hoops. And things are not necessarily trivial even if the support code exists: of all the approaches, this one probably requires the translation layer writer to have the greatest scripting skill and that she learn the most about the application’s internals. Moreover, these tests lead to the same (perhaps slightly greater) doubts about what goes untested as do those of the previous approach, plus one new one: How much should you trust the application to tell the truth about its internals? (Rails says it saved that Order to the database. Why should you believe it?)
Driving the Application layer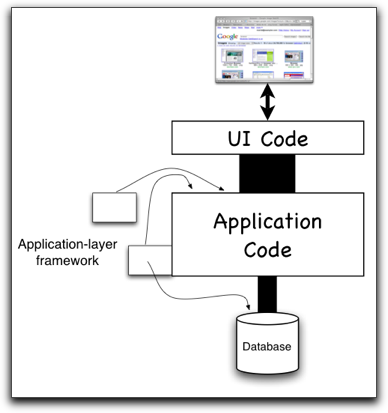
In many systems, especially well-designed ones, there’s a close correspondence between the classes and methods of the code and the nouns and verbs of the business domain. In such systems, the user interface is a way for the user to express clear and simple ideas in a welter of visually-appealing detail. Then the code behind the user interface translates all that detail back into clear and simple classes and methods.
Huh. What if we could go below the user interface altogether?
Many applications have an application controller or workflow layer that orchestrates user tasks. Roughly, a single HTTP request might translate directly into a call to that layer, which then describes (in a fairly abstract way) what the user can do next to what business objects. That description drives the creation of the next screen. You send business language in, get business language out.
Given that our tests are written in business language, having them call the application layer directly makes a lot of sense. (These tests could run within the application, in the Rails style, or they could communicate with the application layer from outside through some web-services-like mechanism.) That probably requires the smallest test translation layer, and one that’s reasonably straightforward to write. Further, because the language of the business is relatively slow to change, these tests will likely break less often than tests that work with some part of the UI layer. Finally, this style meshes well with test-driven design: when the tests come first, they help decide upon the language of the application layer and thus help tune the application to the business.
However, your application either has such a layer or it doesn’t. If it doesn’t, adding it might require a heavy programmer investment. Moreover, that investment is probably not reusable. This isn’t a tool like Watir or HTTPUnit, which can drive any web app, or even the Rails integration test framework, which can be used on any Rails app. Here, everything’s written to one application layer. Moreover, this approach leaves the most untested. Not only are you not testing Javascript, you’re not testing the receipt and processing of HTTP messages or even whether anything like the right HTML is produced. That has to be tested separately.
Summary
All of these approaches—or a combination—can work just fine. I think the most important thing is to keep the number of these tests small. Don’t use Selenium to check any property of the app that can be checked in programmer tests. Don’t automate what’s better tested as a part of manual exploratory testing.
That given, the list above is in my increasing order of bias. That is, despite the Rails framework being way cool, I still like testing against an app layer better.
June 7th, 2007 at 1:03 pm
One to keep. Many thanks. Bob.
June 11th, 2007 at 9:12 am
[…] Друга стаття (Four implementation styles for workflow tests, від Браяна Маріка (Brian Marick)) на вужчу тематику - на тему створення т. з. workflow tests, які показують, як саме користувач виконав те чи інше завдання. […]
June 15th, 2007 at 6:00 am
[…] Workflow tests — разные подходы к автоматизации функциональных тестов […]